Liquid Foundation Models: Next Frontier of AI ?

Is this the next frontier of Transformers ?
Transformers when first introduced in 2017 by Google, literally changed the world, and introduced the common people with AI for the first time unlike self-driving or face recognition. (language based mostly).
All the major LLMs whether from Gemini, OpenAI, Anthropic and other open-source as well are built upon Transformers only.
But Transformer actually has major issues :
- Memory — Transfomers generally has an appetite for memory by a mechanism in them which is “Self-Attention” that needs to store all the input token embeddings and their pairwise attention scores, resulting in high memory usage. (In others words, take a lot of space to remember things)
- Low Customisation for Edge Devices — Inference with Large LLMs (asking questions these LLMs) is memory-intensive, especially when deploying models on edge devices or low-memory environments. Optimising models through techniques such as quantization (reducing precision [like 2.234243 -> 2.24], pruning (removing redundant weights), and using specialised inference frameworks helps manage memory usage but have huge impact on accuracy and performance. This makes no-sense absolutely.
This is where Liquid AI, an AI foundational model company comes into picture. They claim to allow building capable and efficient general-purpose AI systems at every scale. What it means is to have an AI Model for any use case for any device (mostly small for now).
They have introduced Liquid Foundation Models (LFM): First Series of Generative AI Models.
- Basically switching back to the roots of DL, “LFM are Large Neural Networks built with computational units deeply rooted in the theory of dynamic systems, signal processing, and numerical linear algebra.”
- Achieves state-of-the-art performance at every scale
- Maintains small memory footprint
- More efficient and faster inference (calling to LLms, means)
Liquid has introduced 3 Models :
- 1.3B Model : Ideal for resource-constrained environments
- 3.1B Model: Optimised for edge deployment (like mobile devices, etc)
- 40.3B Mixture of Experts (MoE): designed for tacking more complex tasks
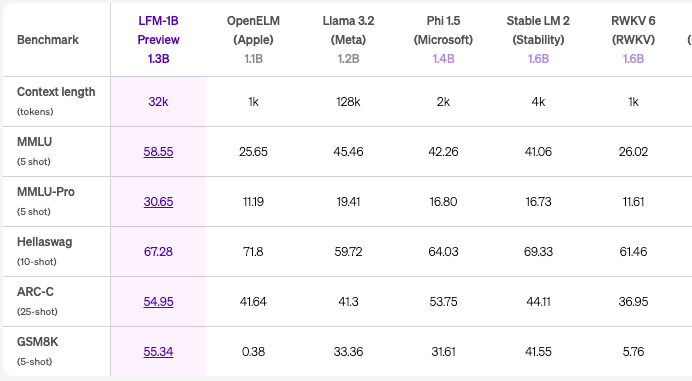
Performance of LFM-1B
- Achieves the highest score across various benchmarks in the 1B category of Models
- New State-of-the-art Model in 1B Category
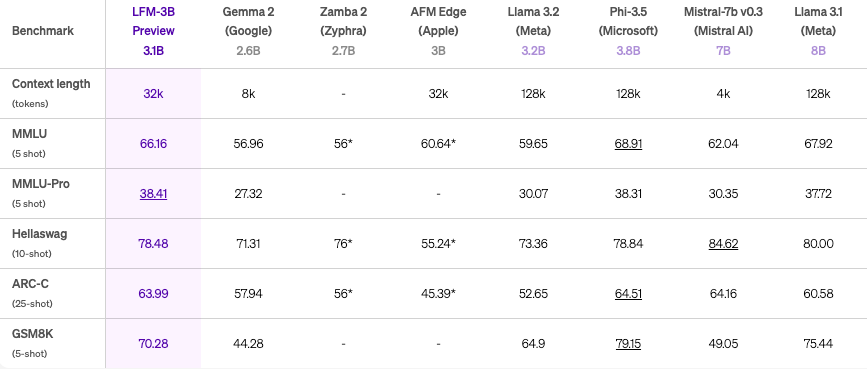
Performance of LFM-3B
- First place among 3B parameters transformers, hybrids, and RNN models
- Outperforms previous generation of 7B and 13B models
- Ideal choice for mobile and other edge text-based applications
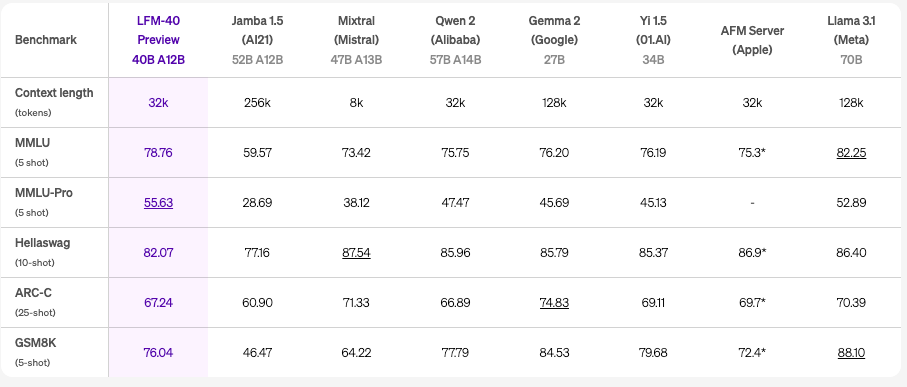
Performance of LFM-40B
- Cost effective only
- Quality and performance similar to other categories of big open-source models
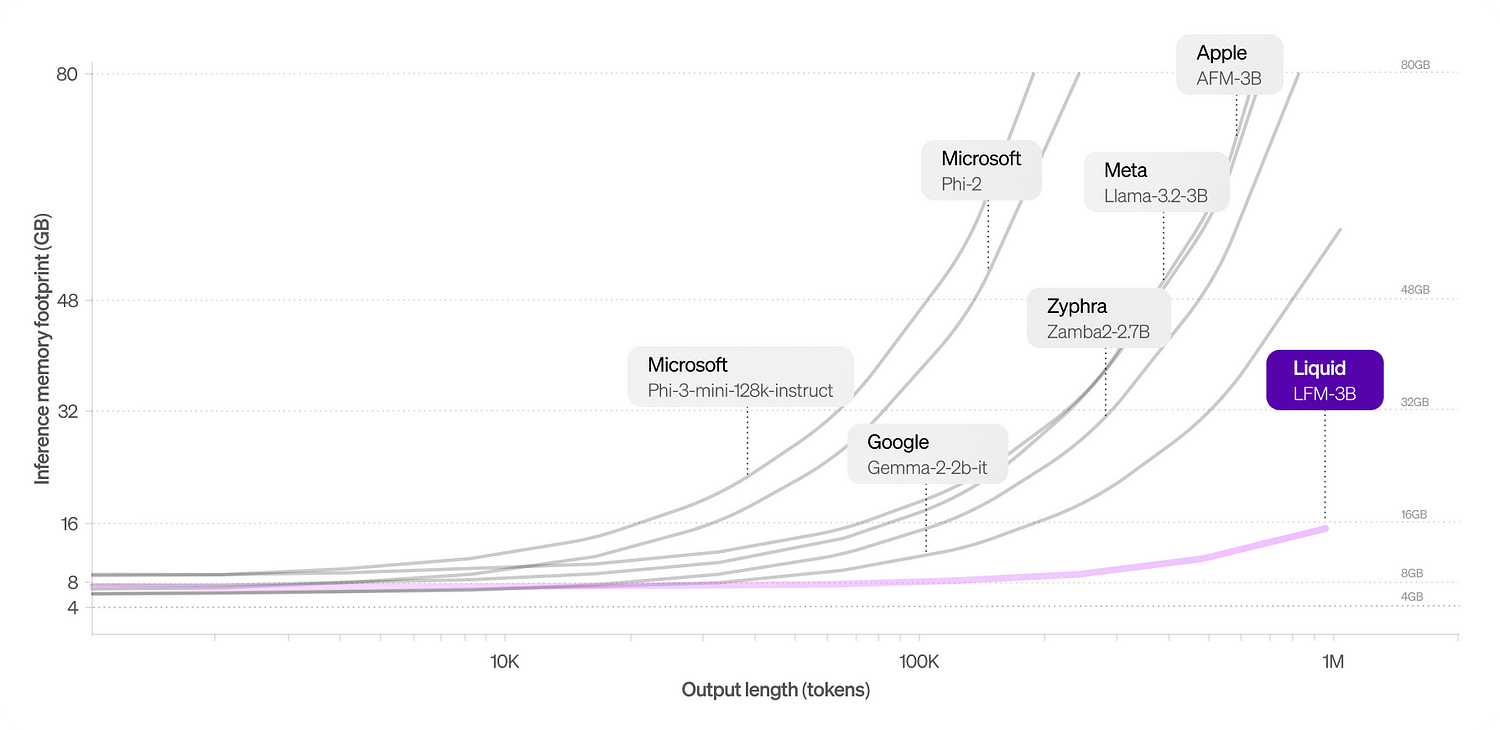
Addressing two major core issues of Transformers
1. Memory efficiency
LFMs are Memory-Efficient.
- LFMs have a reduced memory footprint compared to transformer architecures.
- How did they do it ? Compressing inputs, LFMs can now process longer sequences on the same hardware unlike Transformers where memory consumption grows linearly with sequence length.
- For example, Compared to other 3B category models, LFMs maintain a minimal memory footprint.
Truly Utilising their Context Length
We have seen that some LLMs have humongous context length from 32K to 128K to 256K to even a million by Gemini.
But there is a thing, only certain amount of length is considered as “Effective Length” which means if the input is under this length, the LLM performs better, if I keep it simple.
But with LFMs, thy have optimised their models to deliver a best-in-class 32K token context length, pushing the boundaries of efficiency for the size (atleast for 32K category).

- This is really important. Why ?
- Because this highly efficient context length enables LFMs to perform long-sequence tasks even on edge devices for the first time.
- Creating RAG-based applications, analysing the documents, summarising the long-form content, unlocks a lot of options to develop for edge-devices as well now.
2. Model Architecture + (Customised your AI Model ? )
Some big claims over here by Liquid AI.
- LFMs are composed of structured operators — General claims like reducing memory cost at inference time, increased performance, maximising knowledge capacity and reasoning. (Their research is truly intensie, a lot of work done over there)
- LFM architecture are under control — Claiming to see inside the blackbox, since the LFMs are based on classical signal processing analysis methods only, this might be a great way to inspect the inputs and outputs of the models, and they are doing the same. You see, LLMs are like a magic box, you don’t really know what’s going on there, that’s why LLMs suffers from hallucinations, but with LFMs, Liquid AI says that we can literally inspect the inputs and outputs of these models.
- LFMS are adaptive and can serve as the substrate for AI at every scale — Automatically optimise architectures for a specific platform (from Apple, Qualcomm, and others) or match given parameter requirements and inference cache size. This is actually good, tbh, think about it we don’t need a fully-fledged general model to do our basic summarising task on our mobile phones or laptops. This approach can helps us achieve that, we might only need 100M parameters instead of 1B for very specific use cases.
Customisations (yes,)
Liquid’s design space (their architecture), is primarily defined by featurization and footprint of architectures and their core operators.
Featurization simply means converting your text, audio, images, video, etc., into mathematical representations called vectors (or features). This can be generalised as well like one architecture to rule them all, one framework that converts all data into vectors.
But LFMs has taken a different approach.
For example, audio and time series data generally requires less featurisation due to lower information density, compare to language and multi-model data (images, videos). So you don’t need one single pipeline to process all your data (that’s easy but not efficient)
This allows LFMs to remain efficient in terms of computation requirement. (PS: not much info in their blog on this)
Conclusion
- LFMs are promising but not yet scalable to replace Transformers any-now.
- LFMs are built with computational units that can be expressed as adaptive linear operators whose actions are determined by inputs.
- Don’t require high computation resources as they become big unlike Transformers where the scaling law is holding true (till now).
- LFMs focus on two major things: Memory Efficiency (so they don’t require billions of computational resources), and High Customisation of Models for every scale (so they can be used any where, for any use case).
- LFMs (as they said) can serve as the substrate for AI at every scale.
Try Liquid Models
Reference
- Official — https://www.liquid.ai/
- Models — https://www.liquid.ai/liquid-foundation-models
- Research (PS: They have done a lot, I don’t even get it, going through them for now) — https://www.liquid.ai/blog/liquid-neural-networks-research