Llama 3.1: Open Source’s new Darling
Meta's Llama 3.1, with up to 405B parameters, challenges top AI models. Learn how this open-source breakthrough compares to GPT-4 and Claude, excelling in math, reasoning, and RAG applications.

Open Source AI is the Path Forward — Mark Zuckerberg in his latest post on Meta AI
Must say, after all the controversy regarding Mark’s influence on social media and the data of its users.
In the AI space, he has become the new Linus Torvalds, heavily investing in making open source models as competitive as private LLM models.
Recently, Meta AI released the Llama 3.1 series with 8B, 70B, and 405B models. It’s already at GPT-4 level. This is insane.

Mark released a Facebook post on Why Open Source AI is the Meta is choosing, and below are some points:
- Open source Linux evolved to dominate computing, similar path predicted for AI, new Linus is in the building
- Llama 3 now competitive with leading AI models, literally, infact for RAG applications it is currently the best in the industry.
- Meta releasing Llama 3.1 405B, first frontier-level open source AI model.
- Meta’s strategy: ensure access to best technology without lock-in, just like they did for ReactJs, and GraphQL, it is just building an ecosystem just like Linux.
- Meta actively building partnerships to grow open source AI ecosystem, some examples of Dell, Deloitte, Accenture, and other service companies, no doubt, why service companies is milking the real AI revenue, from their existing enterprise clients, for simple use cases like legal document QnAs.
Overview of Llama 3.1 from recent paper
Introduction
The paper introduces Llama 3, a new set of language foundation models. Key features of Llama 3:
- Native support for multiple languages, coding, reasoning, and tool usage.
- Largest model: 405B parameter dense Transformer with 128K token context window.
- Consists of multiple models referred to as the “Llama 3 Herd”.
- The paper focuses on Llama 3.1 models, referred to as Llama 3 for brevity.
Development and features of Llama 3.1
The paper has pointed out 3 levers or the development and training process of this model:
- Data: Not much in paper, just says pre-trained on a corpus of about 15T multilingual tokens, compared to 1.8T tokens for Llama 2
- Scale: Pre-trained using 3.8 x 10²⁵ FLOPs, in simple words, they used around 16K H100 GPUs.
- Customizations : To support large-scale production inference for the 405B model, they quantized from 16-bit (BF16) to 8-bit (FP8), reducing compute requirements and enabling the model to run on a single server node.
- Native integration of image, video and speech capabilities into Llama 3 using a compositional approach, enabling models to recognize images and videos and support interaction via speech. They are under development and not yet ready for release.
Benchmarks
They are pretty amazing!
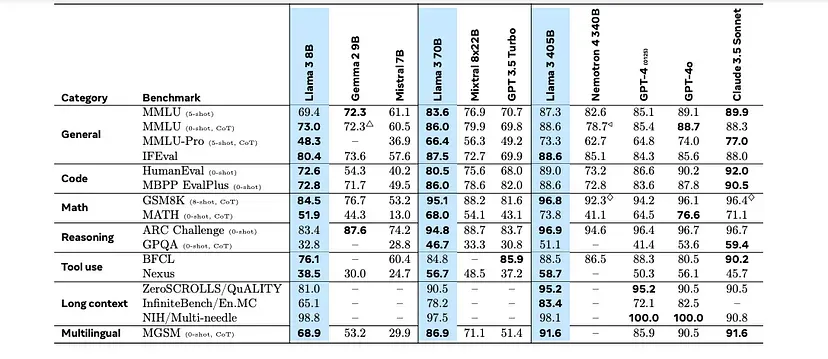
In summary:
- Code: Claude 3.5 Sonnet > GPT-4o > Llama 3.1 405B
- Math: Llama 3.1 405B > Claude 3.5 Sonnet > GPT-4o
- Reasoning: Llama 3.1 405B > Claude 3.5 Sonnet ~ GPT-4o
- IfEval (for RAG/Language Apps) : Llama 3.1 405B > Claude 3.5 Sonnet ~ GPT-4o
- Long Context: GPT-4o( finally!) > Llama 3.1 405B ≥ Claude 3.5 Sonnet
- Multilingual: Llama 3.1 405B ~ Claude 3.5 Sonnet > GPT-4o
Resources: