What are LLMs for beginners ?



Introduction
In this blog, we’ll discuss Large Language Models (LLMs), the force behind several innovations in artificial intelligence recently. This will cover the fundamental concepts behind LLMs, the general architecture of LLMs, and some of the popular LLMs available today.
A Brief History of Large Language Models
The origin of Large Language Models dates back to the 1960s. In 1967, a professor at MIT pioneered the field by creating the very first Natural Language Processing program, Eliza. Eliza employed pattern matching and substitution techniques to comprehend and engage in conversations with humans.
Fast forward to 1970, the MIT team developed another NLP program, SHRDLU, designed to interact effectively with humans.
The year 1988 witnessed the introduction of Recurrent Neural Network (RNN) architecture. RNNs aimed to capture the sequential information inherent in text data. However, they demonstrated limitations, excelling with shorter sentences but struggling with longer ones. In response to this challenge, Long Short-Term Memory (LSTM) was proposed in 1997. This development marked a significant stride in LSTM-based applications, coinciding with the onset of research in attention mechanisms.
While LSTM addressed the issue of handling longer sentences to some extent, it still faced challenges when dealing with extremely lengthy sentences. Additionally, LSTM model training lacked parallelization capabilities, resulting in extended training times.
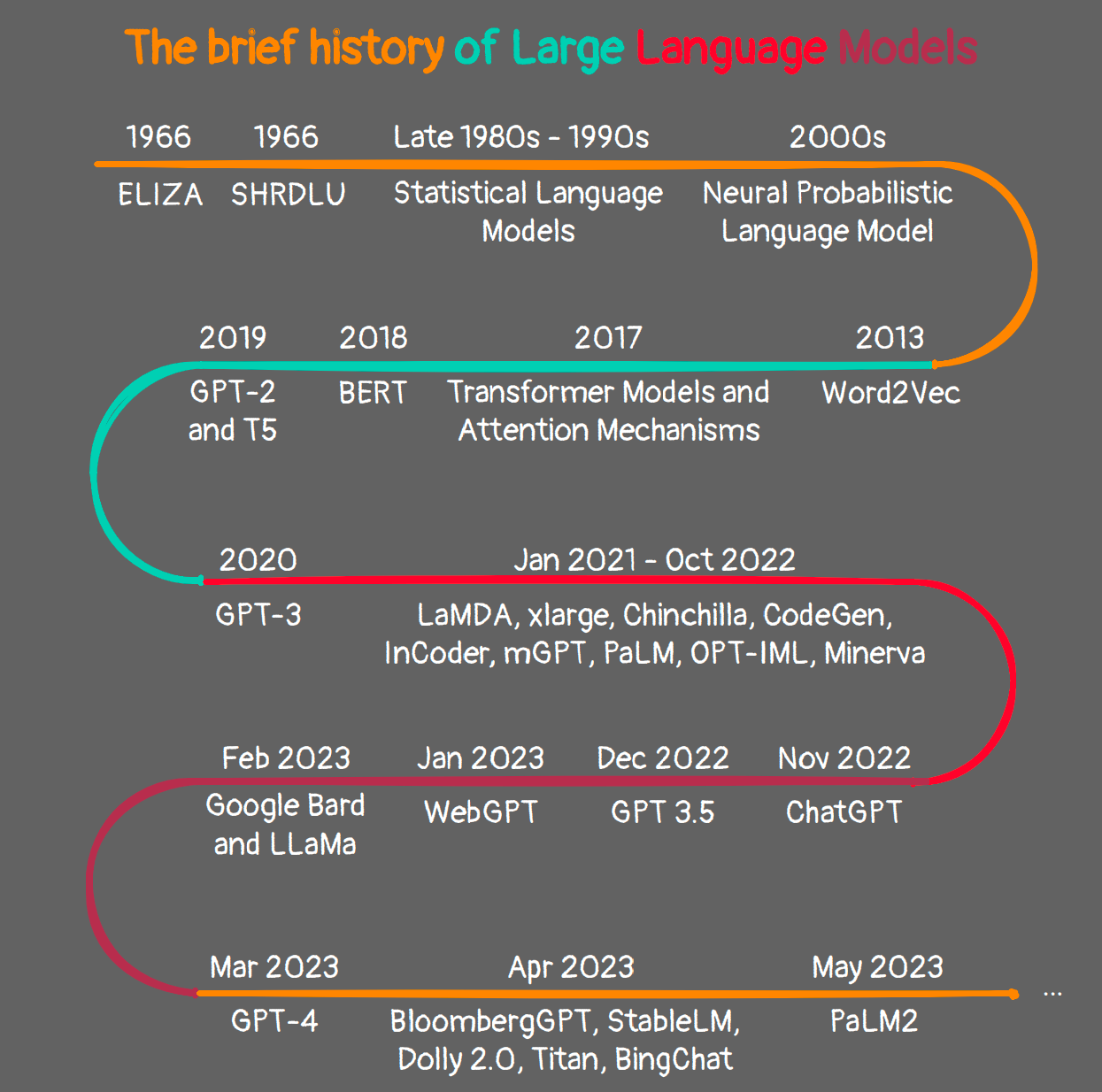
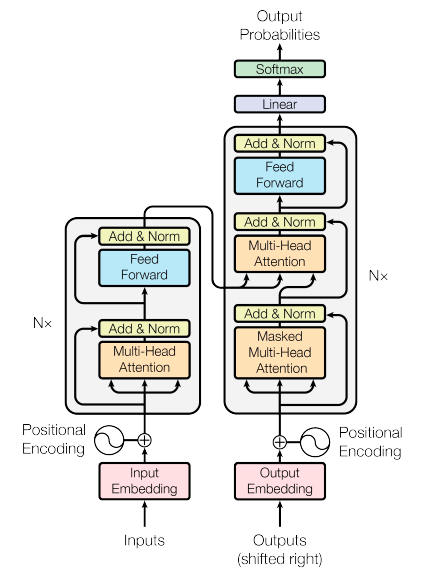
The NLP research landscape experienced a groundbreaking moment in 2017 with the publication of the seminal paper "Attention Is All You Need".
This paper marked a revolutionary turning point in the field of NLP. The researchers introduced a novel architecture known as Transformers, specifically designed to address the limitations of LSTMs. Transformers were distinguished as the inaugural Large Language Models (LLMs), boasting an extensive number of parameters.
These Transformers quickly established themselves as state-of-the-art models within the realm of LLMs. To this day, the ongoing evolution of LLMs continues to be significantly influenced by the transformative impact of the original Transformers.
What are Large Language Models?
In simple terms, Large Language Models are advanced deep learning models meticulously trained on vast datasets to proficiently comprehend human languages. Their fundamental objective is to acquire a nuanced understanding of human languages. What makes Large Language Models exceptional is their ability to process languages much like we, as humans, naturally do.
These models master the intricate patterns and relationships between words within a language. For instance, they discern the syntactic and semantic structures, encompassing grammar, word order, and word and phrase meanings. They possess the remarkable capability to encapsulate the entirety of a language.
However, you might be wondering: how do these Language Models differ from Large Language Models?
Language models are typically statistical models constructed through methods such as Hidden Markov Models (HMMs) or probabilistic-based models. In contrast, Large Language Models are deep learning powerhouses equipped with billions of parameters, finely tuned through extensive training on exceptionally massive datasets.
The Odyssey of Building Large Language Models (LLMs) from Scratch: Challenges and Triumphs
In the ever-evolving landscape of artificial intelligence, Large Language Models (LLMs) have captured the limelight. These behemoths of natural language understanding have redefined the way machines interact with and comprehend human languages. Building LLMs is an epic endeavor, akin to a mythical odyssey. Let's embark on this journey and explore the challenges and triumphs of constructing these linguistic titans from scratch.
The Quest for Data:
One of the initial hurdles is data – colossal amounts of it. To create an LLM that can understand and generate human language, you need an extensive and diverse dataset. This data serves as the bedrock for the model's training. The process of collecting, cleaning, and preparing this data is a monumental task that requires meticulous attention to detail.
Computational Power:
The sheer size and complexity of LLMs demand substantial computational power. Training these models from scratch can take weeks or even months, and it necessitates access to high-performance GPUs or TPUs. The cost involved in procuring and maintaining such hardware can be a significant challenge for both researchers and organizations.
Overfitting and Generalization:
Looming over LLM builders like a specter is the challenge of overfitting. When LLMs are exposed to vast datasets, there's a risk they'll memorize the data instead of genuinely understanding it. Achieving the delicate balance between training a model that memorizes and one that generalizes knowledge is a formidable challenge.
Ethical Concerns:
Building LLMs isn't merely a technical journey; it's also a philosophical one. The potential for LLMs to generate biased or harmful content raises ethical concerns. Safeguarding against misinformation and bias is an ongoing challenge, demanding comprehensive guidelines and rigorous model evaluation.
Size Matters:
A critical challenge is the sheer size of LLMs. Bigger models tend to perform better, but their size introduces practical issues, such as limited deployability in resource-constrained environments, difficulties with fine-tuning, and longer inference times.
Fine-Tuning and Specialization:
While pre-trained models offer a strong foundation, fine-tuning LLMs for specific tasks can be a maze. There's no one-size-fits-all approach. It requires expertise and experimentation to tailor a general LLM for specific applications.
Environmental Footprint:
With great computational power comes great energy consumption. Building LLMs has a significant environmental footprint. This challenge necessitates a push towards more energy-efficient training methods and a consideration of the ecological impact.
The Hero's Journey:
Despite these formidable challenges, building LLMs is a hero's journey. It's about pushing the boundaries of language understanding, enabling machines to converse with us intelligently, and making sense of the vast sea of textual data. The triumph lies in the immense potential LLMs hold to revolutionize education, healthcare, customer service, and beyond.
The odyssey of constructing LLMs is ongoing. As researchers and engineers continue their quest, they seek innovative solutions to these challenges. Each obstacle faced is an opportunity to advance the field and bring humanity closer to machines that truly understand and respond to our words. This is the modern-day epic, and the heroes are the minds behind the Large Language Models of the future.
How do you train LLMs from scratch ?
Decoding the Mysteries of Training Large Language Models (LLMs) from Scratch
In the realm of artificial intelligence, Large Language Models (LLMs) stand as mighty sentinels of natural language processing. They are the bedrock upon which countless AI applications are built. But what truly goes into the arduous process of training these colossal linguistic engines from the ground up? This journey takes us deep into the technical intricacies of LLM training.
1. Data: The Bedrock of Language Learning
To initiate the construction of an LLM, a colossal volume of textual data is required. However, it's not just the quantity that matters; quality and diversity are equally vital. These data repositories must span various languages, subjects, and writing styles to ensure the model understands an extensive range of linguistic nuances.
2. Data Preprocessing: Untangling the Linguistic Web
Raw text data is a labyrinth, and to train an LLM effectively, it needs to be tamed. Data preprocessing is the art of cleaning, structuring, and tokenizing this data. It divides the text into smaller, manageable units like words or subwords. This step makes data digestible for the model, allowing it to understand language's intricate web.
3. Model Architecture: Transformers and Beyond
The heart of an LLM is its architecture. While earlier models like RNNs and LSTMs played pivotal roles in language understanding, the transformative architecture of LLMs like transformers has redefined the landscape. These models, characterized by their parallelizability and ability to capture long-range dependencies, are the driving force behind state-of-the-art LLMs.
4. Training: Where Magic Meets Computation
Training an LLM is akin to teaching a machine the art of language. This process involves exposing the model to the vast dataset, iteratively fine-tuning its internal parameters to minimize errors, and enhancing its linguistic capabilities. It's a resource-intensive undertaking that demands access to high-performance GPUs or TPUs, leading to energy and infrastructure challenges.
5. Overcoming Challenges: The Quest for Perfection
LLM development isn't without its perils. Challenges include mitigating overfitting, addressing ethical concerns like bias and misinformation, optimizing model size for real-world usage, and navigating the complexities of hyperparameter tuning to strike the right balance between model size and accuracy.
6. Specialization via Fine-Tuning: Art Meets Technology
Once the foundational model is trained, fine-tuning takes center stage. It's a process of honing the LLM for specific tasks. This involves adapting the model for applications such as machine translation, chatbots, or content generation. It's a precise and nuanced endeavor, blending the LLM's inherent language understanding with domain-specific knowledge.
In essence, training LLMs from scratch is a technical odyssey through the realms of data processing, model architecture, computational might, and ethical considerations. It's a heroic quest to empower machines to wield the power of language with ever-increasing fluency and sophistication. As we journey forward, LLMs continue to evolve, reshaping our AI interactions and how AI interfaces with our world. The narrative of LLMs is far from over, with each chapter bringing us closer to an AI-augmented linguistic utopia.
Conclusion
In the thrilling journey of training Large Language Models (LLMs) from scratch, we've discovered the magical fusion of art and science. The stages, from data acquisition and preprocessing to transformer architecture and fine-tuning, represent milestones in the quest to empower machines with the mastery of human language.
Yet, this venture is not devoid of challenges. Battling overfitting, addressing ethical considerations, and optimizing model size are formidable tasks. These hurdles form the crucible through which LLMs are refined for specialized tasks, transcending from data-driven technology to linguistic artistry.
The saga of training LLMs unfolds against the backdrop of boundless AI potential. In this unfolding narrative, LLMs are redefining how we interact with technology and, in turn, how machines understand and respond to our linguistic world. As we peer into the future, we see LLMs poised to be our linguistic companions, ushering us into an era where AI is an integral part of the conversation, a true connoisseur of language, and a beacon of communication.